당신은 구글이 아닙니다 (You Are Not Google) / 번역
[원문] / Oz Nova (2017)
소프트웨어 엔지니어들은 정말 별것 아닌 일에도 열광합니다. 우리는 스스로를 극도로 이성적인 존재라 생각하지만, 실제로 어떤 기술을 선택할 때 보면 정신없는 광란에 빠지곤 합니다. 한 사람의 해커 뉴스 댓글에서 또 다른 사람의 블로그 포스트로 이리저리 튕기다가, 결국은 가장 눈에 띄는 기술을 향해 무력하게 끌려가 바닥에 눕게 됩니다. 우리가 처음에 무엇을 찾고 있었는지조차 잊은 채로 말이죠.
이건 이성적인 사람들이 결정을 내리는 방식이 아닙니다. 하지만 소프트웨어 엔지니어들이 MapReduce를 선택하는 방식은 바로 이렇습니다.
UC 버클리의 Joe Hellerstein 교수가 학부 데이터베이스 수업에서 이렇게 말했습니다 (54분 경):
“세상에 그 정도 규모의 작업을 처리하는 회사는 다섯 곳 정도밖에 없습니다. 나머지 사람들은… 필요도 없는 장애 허용성을 위해 I/O를 낭비하고 있죠. 2000년대에는 다들 구글 망상에 빠졌습니다. ‘우리는 세계에서 가장 큰 인터넷 데이터 서비스를 운영하니까 구글처럼 해야 해!’ [고개를 갸웃거리며 웃음을 기다림]”

필요 이상의 장애 허용성이 정말 괜찮을까?
장애 허용성(fault tolerance)이 과하다면 그 자체로는 문제가 없어 보일 수도 있습니다. 하지만 그에 따른 비용을 생각해보세요. 단순히 I/O가 늘어나는 것만이 아니라, 트랜잭션, 인덱스, 쿼리 최적화기 같은 기능이 있는 성숙한 시스템을 버리고 기능이 빈약한 시스템으로 전환하게 될 수도 있습니다. 그건 커다란 후퇴입니다. Hadoop 사용자 중 과연 몇 명이나 이런 절충점을 의식적으로 선택했을까요? 또 그 중 몇 명이나 현명하게 선택했을까요?
요즘은 MapReduce나 Hadoop이 공격받기 쉬운 대상입니다. 왜냐하면 이제는 모방꾼들조차도 더 이상 비행기가 날아오지 않는다는 걸 깨달았기 때문이죠. 하지만 이와 비슷한 이야기는 더 넓은 범위에서도 할 수 있습니다. 만약 당신이 어떤 대기업에서 만들어진 기술을 쓰고 있는데, 그 기업과 당신의 사용 사례가 매우 다르다면, 당신은 그 기술을 의도적으로 선택한 게 아닐 가능성이 높습니다. 오히려 “거인을 따라하면 부자가 될 수 있다”는 의식화된 믿음에 따른 결과일 것입니다.
그러니 맞습니다. 이 글도 결국 “카고 컬팅(cargo culting, 무비판적인 모방)”을 하지 말자는 이야기입니다. 하지만 잠깐! 저는 여러분이 더 나은 결정을 내릴 수 있도록 돕는 유용한 체크리스트를 하나 소개하려 합니다.

멋진 기술? UNPHAT을 따르세요
다음에 당신이 어떤 멋진 신기술을 찾아 아키텍처를 다시 짜고 싶어질 때, 그 전에 꼭 UNPHAT을 떠올리세요:
-
U — Understand (문제 이해하기)
해결책을 고민하기 전에 문제를 제대로 이해하세요. 가능한 한 ‘해결 영역’이 아닌 ‘문제 영역’ 안에서 문제를 해결하려 노력해야 합니다.
-
N — eNumerate (여러 후보 나열하기)
좋아하는 기술 하나만 만지작거리기 시작하지 말고, 가능한 여러 대안을 생각해 보세요.
-
P — Paper (논문 읽기)
후보 기술이 있다면, 그것이 어떤 논문이나 백서에서 출발했는지 찾아 읽어보세요.
-
H — Historical context (역사적 배경 이해하기)
그 기술이 만들어졌던 시대적 배경과 맥락을 이해하세요.
-
A — Advantages (장점 vs 단점)
무엇을 우선시하기 위해 무엇을 희생했는지 비교하고 평가하세요.
-
T — Think (생각하기)
이 기술이 정말로 당신의 문제에 적합한지, 차분하고 겸손하게 고민하세요.예를 들어: “이 데이터를 Hadoop을 쓰지 않고도 처리할 수 있으려면, 데이터의 크기가 어느 정도여야 할까?”
당신은 아마존도 아닙니다 (You Are Not Also Amazon)
UNPHAT을 실제로 적용하는 건 꽤 단순합니다. 최근 어떤 회사와 이야기하면서, 그들이 Cassandra를 고려 중이라는 얘기를 들었습니다. 그들의 워크로드는 주로 읽기 작업이었고, 데이터는 밤마다 한 번에 로드되었습니다.
저는 Dynamo 논문을 읽어봤고, Cassandra가 그것에서 파생된 시스템임을 알고 있었습니다. 이런 분산 데이터베이스는 쓰기 가용성을 최우선으로 합니다. (아마존은 “장바구니에 담기” 기능이 절대 실패하지 않도록 하길 원했죠.) 하지만 이는 일관성을 희생하고, 전통적인 RDBMS의 거의 모든 기능을 버리는 대가를 치른 것이었습니다. 그런데 그 회사는 쓰기 가용성을 중요시할 필요가 없었습니다. 하루에 한 번만 크게 데이터를 쓰면 되었기 때문입니다.

이 회사가 Cassandra를 고려한 이유는 PostgreSQL 쿼리 성능이 몇 분씩 걸리기 때문이었습니다. 하드웨어의 한계일 거라 생각한 거죠. 몇 가지 질문을 통해 우리는 해당 테이블이 약 5천만 행이고, 각 행이 80바이트라는 사실을 알아냈습니다. 전체를 SSD에서 읽는다고 가정하면 약 5초 정도 걸리는 수준이죠. 느리긴 하지만, 실제 쿼리보다는 두 자릿수나 빠른 속도였습니다.
이쯤 되면 더 많은 질문을 하고 싶어졌습니다. (문제를 이해하라!) 그리고 벌써 5가지 정도의 대안 전략을 떠올리고 있었죠. (대안을 나열하라!) 하지만 이 시점에서 이미 Cassandra는 전혀 맞지 않는 선택임이 분명했습니다. 필요한 건 참을성 있는 튜닝, 데이터 모델 재설계, 아니면 (정말 필요한 경우에 한해서) 다른 기술을 선택하는 것이었습니다. 하지만 분명한 건, 쇼핑카트를 위한 고가용성 쓰기용 키-값 저장소는 아니었다는 점입니다.
당신은 링크드인도 아닙니다 (Furthermore, You Are Not LinkedIn)
한 학생의 회사가 시스템을 Kafka 중심으로 설계했다고 들었을 때, 저는 꽤 놀랐습니다. 왜냐하면 그들의 비즈니스는 하루에 수십 건의 고부가가치 트랜잭션만 처리했기 때문입니다 — 잘 되어봐야 하루에 수백 건 정도였죠. 이 정도 처리량이면, 주 데이터 저장소는 사람이 직접 수기 장부에 쓰는 방식으로도 충분했을 정도입니다.
이에 비해 Kafka는 본래 링크드인에서 분석 이벤트 전체를 처리하기 위해 설계된 것입니다. 정말 어마어마한 양이죠. 불과 몇 년 전만 해도 링크드인은 하루에 약 1조 개의 이벤트를 처리했고, 초당 천만 건 이상의 메시지 피크를 기록했습니다. 물론 Kafka는 낮은 처리량의 작업에도 쓸 수 있습니다. 하지만 10자릿수 차이라면 이야기가 달라집니다.

아마도 그 회사의 엔지니어들은 실제 요구사항과 Kafka의 설계 의도를 잘 이해한 뒤에 신중하게 결정했을 수도 있습니다. 그러나 제 추측은 그들이 커뮤니티에서 형성된 (어느 정도는 정당한) 열광에 휩쓸렸고, 그것이 과연 그들의 작업에 적합한 선택인지 깊이 고민하지 않았다는 것입니다. 다시 말하지만… 10자릿수 차이는 좀 과하잖아요?
다시, 당신은 아마존도 아닙니다 (You Are Not Amazon, Again)
Amazon의 분산 데이터 저장소보다 더 유명한 것은, 아마 그들이 규모를 확장하는 데 결정적인 역할을 했다고 알려진 아키텍처 패턴일 것입니다. 바로 서비스 지향 아키텍처(SOA) 입니다. 2006년, Jim Gray가 Werner Vogels를 인터뷰하면서 Amazon이 2001년에 프론트엔드 확장 문제를 겪었고, SOA가 해결책이 되었다는 이야기가 전해졌습니다. 이 말은 한 엔지니어에서 다른 엔지니어로 전해지며, 사용자가 거의 없고 개발자 몇 명뿐인 스타트업들조차도 자기네 브로셔 수준의 앱을 나노서비스로 쪼개기 시작했습니다.
하지만 Amazon이 SOA로 전환을 결심했을 때는 직원 수가 약 7,800명, 연매출은 30억 달러 이상이었습니다.

그렇다고 해서, 당신이 7,800명 규모가 될 때까지 SOA를 도입하지 말라는 얘기는 아닙니다. 다만, 스스로 생각하세요. 그게 정말 당신 문제의 최적 해법인가요? 애초에 당신의 문제가 정확히 뭔가요? 다른 해결책은 없을까요?
만약 당신이 “우리 개발팀이 50명인데 SOA 없이는 프로젝트가 마비돼요”라고 말한다면, 저는 이렇게 되묻고 싶습니다. “그보다 훨씬 큰 조직들도 하나의 잘 구성된 애플리케이션만으로 잘 돌아가고 있는데요?”
구글조차 구글이 아닙니다 (Even Google Is Not Google)
Hadoop이나 Spark 같은 대규모 데이터플로우 엔진 사용은 특히 더 우습게 느껴질 수 있습니다. 대부분의 경우, 전통적인 RDBMS가 훨씬 더 적합한 작업이 많고, 심지어 데이터 용량이 너무 작아서 메모리에 다 올려버려도 될 정도인 경우도 많습니다. 요즘은 램 1TB도 약 1만 달러면 살 수 있습니다. 사용자 수가 10억 명이라 해도, 사용자당 1KB의 램을 쓸 수 있는 셈입니다.
물론 당신의 워크로드에는 이 정도로는 부족할 수도 있고, 디스크에 읽고 쓰는 작업이 필요할 수도 있습니다. 하지만 정말로 수천 개의 디스크를 읽고 써야 할 정도인가요? 당신의 데이터는 정확히 얼마나 많은가요?
GFS와 MapReduce는 전체 웹을 대상으로 연산하기 위해 만들어졌습니다. 예컨대 전체 웹을 다시 인덱싱하는 작업 같은 것 말이죠.
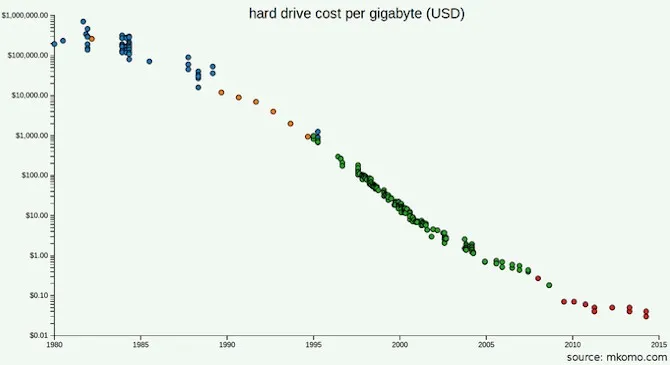
혹시 당신은 GFS와 MapReduce 논문을 읽고, 구글이 직면했던 진짜 문제는 용량이 아니라 처리량이었다는 점을 이해했을 수도 있습니다. 그들은 디스크에서 바이트를 스트리밍하는 데 너무 오래 걸렸기 때문에 저장소를 분산시킨 것이었습니다. 하지만 2017년의 장비 처리량은 어떤가요? 구글처럼 많은 장비가 필요하지 않다면, 그냥 더 나은 장비를 사면 되는 것 아닌가요? SSD는 어떤가요? 비용은 얼마나 드나요?
미래에 확장할 가능성도 있겠지만, 계산은 해봤나요? SSD 가격 하락 속도보다 더 빠르게 데이터를 쌓게 될 가능성이 있나요? 당신의 비즈니스가 얼마나 커져야 하나의 머신에 데이터를 담을 수 없게 될까요?
예를 들어, 2016년 Stack Exchange는 하루 2억 건의 요청을 처리했습니다. 이때 사용된 SQL 서버는 단 4대뿐이었습니다 — Stack Overflow용 마스터 1대, 나머지 전체용 마스터 1대, 그리고 복제본 2대.
물론 UNPHAT 절차를 거친 끝에 Hadoop이나 Spark를 선택할 수도 있습니다. 때로는 그게 정말 맞는 선택이 될 수도 있죠. 중요한 건, 그 결정이 진짜로 ‘문제에 맞는 도구’를 선택한 결과냐는 것입니다.
구글은 이 점을 잘 알고 있었습니다. 결국 그들은 MapReduce가 검색 인덱스를 만드는 데 더 이상 적합하지 않다고 판단했고, 그 사용을 중단했습니다.
먼저, 문제를 이해하라 (First, Understand the Problem)
제가 전하려는 메시지가 새롭지는 않을지도 모릅니다. 하지만 어쩌면 이 버전이 당신에게는 더 잘 와닿을 수도 있고, UNPHAT이라는 약어가 기억하기 쉬워서 실제로 활용하게 될 수도 있습니다. 그렇지 않다면, 다음 중 하나를 시도해보세요:
- Rich Hickey의 강연 〈Hammock Driven Development〉
- George Pólya의 책 《문제를 어떻게 풀 것인가 (How to Solve It)》
- Richard Hamming의 강의 〈The Art of Doing Science and Engineering〉
우리가 모두 한 목소리로 호소하고 있는 것은 바로 이것입니다:
생각하라! 그리고 당신이 해결하려는 문제를 실제로 이해하라.
Pólya 의 책에서 인상적인 문장을 빌리자면 이렇습니다:
“당신이 이해하지도 못한 질문에 대답하는 것은 어리석은 일이다. 당신이 원하지도 않는 목적을 위해 노력하는 것은 슬픈 일이다.”