자바의 원시 타입을 사용하지 말자
정확히 말하면 ‘비즈니스 도메인’을 나타내는 모델에서 자바 원시 타입을 사용하지 말자고 말하고 싶다.
구글에 자바의 원시 타입과 박싱 타입과 관련된 키워드로 검색하면, 박싱된 기본 타입 사용을 지양하자는 블로그 글이 많이 나온다. 대부분 이펙티브 자바 (Effective Java 3/E, Joshua J. Bloch) 의 Item 61 에서 언급하는 내용을 인용하며 그 차이점과 단점에 대해 서술하고 있다. 그렇다면 그러한 단점들은 어떤 것들이 있으며, 실제 어플리케이션 개발에서 얼마나 큰 영향을 미칠까?
박싱된 기본 타입의 식별성 문제
박싱된 기본 타입은 식별성을 가지고 있기 때문에 두 객체가 같은지를 비교할 때 == 연산자를 사용할 수 없다. 동일성이 없기 때문이다. == 연산자는 두 객체의 주소값을 비교하기 때문에, 박싱된 기본 타입의 경우 equals() 메소드를 사용해야 한다.
Integer a = 1;
Integer b = 1;
System.out.println(a == b); // false
System.out.println(a.equals(b)); // true
분명 a 와 b 는 같은 값을 가지고 있지만, == 연산자를 사용하면 false 가 출력된다. 이는 분명 실수를 유발할 수 있는 부분이다. 또한 equals() 메소드를 사용하면 a 의 null 여부를 확인해야 해서 번거롭기도 하다. 하지만 이러한 부분들이 모든 상황에서 꼭 단점이라고 할 수는 없다.
원시 타입은 반드시 0 이나 false 와 같은 기본 값을 가져야 한다. 하지만 현실 세계를 모델링 하는 비즈니스 어플리케이션에서는 어떠한 값이 ‘존재하지 않는’ 상태가 있을 수 있다. 비즈니스 모델에서 int, long 등으로 표현되는 숫자가 특정한 코드나 ID 등을 나타낸다면 기본 값 0 을 특수한 케이스로 취급할 수 있겠지만 수량, 금액등의 셀 수 있는 개념을 나타내는 데 사용된다면 0 으로는 해당 값이 존재하지 않는 상태와 실제 값이 0 인 상태를 구분할 수 없다. 결국 이러한 상태를 표현하기 위해서는 null 을 사용해야 할 수밖에 없다.
또한 외부 API 를 사용할 때도 비슷한 일이 발생할 수 있다. 외부 API 에서 JSON 형태로 자료를 제공하고 어플리케이션에서 이를 파싱하여 사용한다고 가정해보자. 이 때 특정한 JSON 필드가 null 또는 undefined 인 상황이 발생한다면, 역직렬화 할때 사용하는 라이브러리나 설정에 따라 다르겠지만 원시 타입을 사용할 경우 의도되지 않은 값으로 초기화 될 수 있다.
[
{
"userId": 1,
"name": "Jane",
"vip": false,
"balance": 0
},
{
"userId": 2,
"name": "Smith",
"vip": null,
"balance": null
}
]
class User {
private int userId;
private String name;
private boolean vip;
private int balance;
}
위 JSON 배열을 역직렬화 하여 User 객체를 생성한다고 가정해보자. balance 필드는 int 타입으로 선언되어 있기 때문에 null 을 가질 수 없다. 따라서 balance 필드는 0 으로 초기화 될 것이다. 마찬가지로 vip 필드도 false 로 초기화 될 것이다. 이러한 상황은 의도되지 않은 값으로 사용자 Jane 과 Smith 가 어플리케이션에서 동등하게 취급되어 오류를 야기할 수 있다. 이러한 부분은 직접 외부 서비스의 응답과 역직렬화된 데이터를 비교하지 않는 이상, 상당히 발견하기 어려운 오류이다.
박싱된 기본 타입의 성능 문제
분명 기본타입을 박싱하고 언박싱 하는데에는 성능상의 비용이 든다. 다음은 많은 블로그에서 인용하는 예제이다.
@Test
void primitiveTypeSum() {
long sum = 0L;
for (long i = 0; i <= Integer.MAX_VALUE; i++) {
sum += i;
}
System.out.print(sum);
}
@Test
void wrapperTypeSum() {
Long sum = 0L;
for (long i = 0; i <= Integer.MAX_VALUE; i++) {
sum += i;a
}
System.out.print(sum);
}
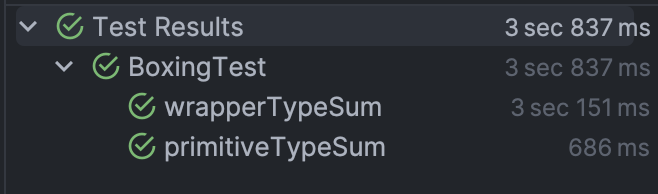
실제로 테스트를 해 보면 기본 타입을 사용한 경우가 박싱된 타입을 사용한 경우보다 약 4.5배 정도 빠르다. 꽤 무시하기 힘든 성능 차이인 것 같다. 하지만 이를 최적화 하기 전에 정말 성능이 중요한 부분인지를 고민해봐야 한다. 이러한 성능 차이가 실제 어플리케이션에서 큰 영향을 미칠까?
많은 비즈니스 어플리케이션의 핵심 로직은 데이터베이스와 연동되어 데이터를 조회하고, 이를 가공하여 사용자에게 제공하는 과정으로 이루어져 있다. 필요한 경우 다른 원격 서비스를 호출하기도 한다. 이러한 자바 프로세스 외부에서 발생하는 시간 지연은 기본 타입의 박싱, 언박싱 비용보다 어마어마하게 크다. 따라서 비즈니스 로직에서 매우 성능 집약적인 수치 계산이 일어나지 않는 한 기본 타입의 박싱, 언박싱 비용은 무시해도 좋으며 박싱, 언박싱이 일어나는 상황에서의 최적화가 어려운 일도 아니다.
자바의 근본적인 문제
또 원시 타입 사용을 지양해야 할 이유로 ArrayList 와 같은 컬렉션에 원시 타입을 사용할 수 없다는 점이 있다. <Integer> 는 존재하지만 <int> 는 불가능하다. 자바는 제네릭이 나오기 전에 설계된 언어이기 때문에 컬렉션이 원시타입을 지원하지 못한다. 템플릿 변수가 컴파일을 거치면 실제 타입별 코드로 변환되는 C++ 과 다르게 제네릭을 사용한 타입이 컴파일을 거치면 모두 Object 타입으로 변환된다. 이는 제네릭을 사용하는 컬렉션에 원시 타입을 사용할 수 없다는 것을 의미한다.
원시 타입을 사용할 수 있는 자료구조는 array 뿐이고 유연하게 사용할 수 없기 때문에 결국 Map, Set 등 다양한 자료구조를 활용하기 위해 박싱된 기본 타입을 사용해야만 한다. 선언적으로 데이터 가공을 정의할 수 있는 Java 11 의 Stream API 를 사용할 때도 마찬가지다. Stream 은 원시 타입을 사용할 수 없다. IntStream, LongStream 등의 원시 타입 스트림을 제공하긴 하지만 API 구성에 있어 제네릭 기반의 스트림을 사용하는 것이 훨씬 유연하다.
박싱된 기본 타입의 미래
자바에서는 박싱 타입에 대한 성능 개선 작업을 지속하고 있으며 새로운 자바 버전이 나올때 마다 꾸준히 개선되고 있다. 특히 Project Valhalla 에서는 메서드, 제네릭 실행 기능과 같은 클래스의 모든 장점을 갖지만 동일성은 없는 클래스인 ‘값 클래스’, ‘원시 클래스’ 도입 등 박싱된 기본 타입의 성능을 향상시키기 위해 여러 가지 방법을 고안하고 있으므로 앞으로 자바에서 박싱된 기본 타입을 사용하는 것이 더욱 유리해질 것이다.