
같은 리소스에 대해 DELETE /resource/{id} 와 같이 클라이언트에서 http delete 메서드를 두 번 호출하면 서버에서는 응답 코드로 무엇을 반환해야 할까? ‘존재하지 않는 리소스’ 에 대한 삭제 요청이니 404 Not Found 여야 할까? 아니면 ‘이미 삭제된 것을 삭제’ 하는 멱등한 연산이니 200 OK 를 줄 수도 있지 않을까?
HTTP Delete 는 멱등하다?

수학에서 멱등(冪等, idempotent) 이란 f(f(x)) = f(x) 를 만족하는 함수를 말한다. 즉, 함수를 여러 번 적용해도 ‘결과’가 달라지지 않는다는 것이다. RFC7231 에 따르면, HTTP 메서드 중에서 멱등한 메서드로는 GET, PUT, DELETE 를 들 수 있다. GET 은 조회이므로 당연히 멱등하다. PUT 은 리소스를 생성하거나 갱신하는데, 같은 리소스에 대해 여러 번 호출하면 동일한 결과로 리소스를 갱신하는 것이므로 결과는 같다. DELETE 도 마찬가지로 여러번 삭제를 호출해도 리소스는 삭제된 상태로 동일할 것이다.
반면, 멱등하지 않은 메서드로는 POST, PATCH 를 들 수 있다. POST 는 리소스를 생성하는데 같은 요청을 여러 번 호출하면 리소스가 여러 개 생성되므로 멱등하지 않다. 한편, PATCH 는 리소스를 부분 갱신한다. 예를 들어 PATCH 메서드로 사용자의 장바구니에 상품을 추가하는 요청을 여러 번 보낸다고 하면, 같은 상품이 여러개 추가되므로 멱등하지 않다.
HTTP 메서드의 성질
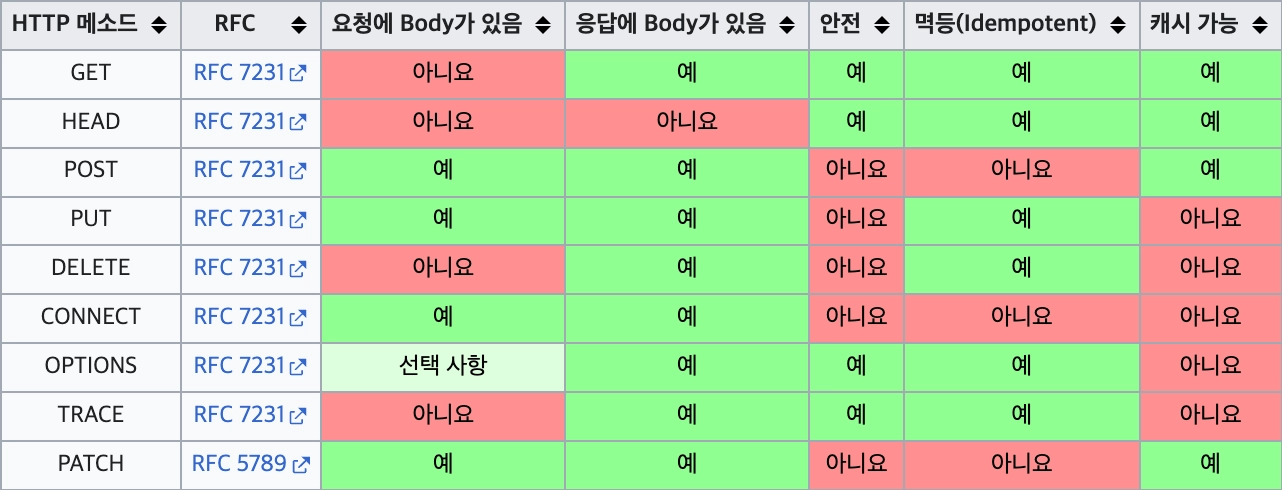
HTTP 멱등의 의미는 RFC7231 4.2.2 에서 더 자세히 살펴볼 수 있는데, 결국 핵심은 멱등의 ‘결과’란 리소스(서버)의 상태를 말한다는 것이다. 따라서 응답 코드나 응답 본문에 대해서는 멱등성을 보장하지 않으며 이는 선택의 문제이다. 즉, DELETE 메서드는 멱등하지만 응답 코드 및 응답 바디는 멱등하지 않을 수 있다는 것이다.
API 스펙으로서의 HTTP 상태코드의 모호함
초기 HTTP는 서버에 있는 파일이나 문서에 대한 요청을 처리하기 위해 설계되었다. 그래서 기본적으로 응답 코드는 원격 서버에 있는 파일이나 문서의 상태를 나타내기 위해 만들어졌다. 예를 들어 404 Not Found 는 말 그대로 클라이언트가 요청한 URI 의 리소스가 서버에 없다는 것을 나타내고, 201 Created 는 서버에 리소스가 생성되었다는 것을 나타낸다.

REST 원칙을 기반으로 설계된 API 에서는 리소스가 파일이나 문서가 아니라 비즈니스 객체를 나타내는 경우가 많다. 이때 대부분 비즈니스 객체에 대한 상태를 응답 코드에 대응 시킬 수 있지만 간혹 비즈니스 이외의 논리가 개입되어 상태 코드의 의미가 모호해지는 경우가 있다. 예를 들어 GET /resource/{id} 를 호출할 때 404 Not Found 를 반환 받았다고 하자. 직관적으로 생각할 때는 id 에 대응하는 객체가 존재하지 않는다고 생각할 수 있지만, 실제로는 서버에 해당 요청을 처리하는 코드가 없어서 WAS 에서 404 Not Found 를 반환하는 경우일 수도 있다. 이 경우에는 클라이언트는 리소스가 존재하지 않는다고 오해할 수 있다.
이런 문제는 근본적으로 두 가지 계층, 즉 클라이언트와 WAS 간의 통신과 어플리케이션 내부의 비즈니스 로직의 결과가 HTTP 응답 하나만으로 처리되기 때문에 발생한 문제이다. 개발자가 코드로 리소스에 대한 생성, 삭제, 수정과 같은 기능을 구현할 때에는 각각 기능에 대응되는 메서드와 응답을 정의하고 필요에 따라 언어에서 지원하는 예외를 정의하여 구현하지만 이를 HTTP 프로토콜로 노출할 때에는 각 메서드에 대한 접근을 URI 로, 메서드의 응답을 바디와 상태 코드로 표현해야 하기 때문에 변환 과정에서 불일치가 발생하는 것이다.
API 의 HTTP 상태 코드 선택에 대한 여러 관점
앞서 말한 ‘멱등함은 서버의 상태에만 적용된다’는 점과, ‘HTTP 상태코드는 모든 비즈니스 상태에 명확히 대응될 수 없다’는 점을 고려하면, HTTP 로 노출되는 API 를 설계할 때 상태 코드를 어떻게 정의해야 하는가에 대한 명확한 정답은 없다. 다만 API 가 사용되는 상황과 사용자의 편의성을 고려해 몇가지 관점을 고려해볼 수 있다.
서버의 API 자체를 리소스로 취급하기
첫 번째 관점은 서버가 제공하는 API 자체만을 리소스로 취급하는 것이다. 이 관점에서는 API 자체가 리소스이므로, 일단 클라이언트가 API 를 정상적으로 호출하기만 했으면 200 OK 를 상태 코드로 반환한다. 그밖에 비즈니스적 예외 상황이 발생했을 경우에는 200 OK 를 유지하며 응답 바디에 예외 상황에 대한 정보를 담아 반환한다. 404 Not Found 는 클라이언트에서 정말 서버에 존재하지 않는 API 를 호출했을 때 발생한다.
이런 방식의 경우 클라이언트는 API 를 호출했을 때 항상 200 OK 를 반환받으므로 상태 코드에 대한 모호함은 해결할 수 있다. 그러나 클라이언트가 예외 상황에 대한 처리를 하기 위해서는 응답 바디를 파싱해야 하므로 클라이언트의 부담이 늘어난다는 단점이 있다. 한편, 대다수의 서버 모니터링 도구는 상태 코드만을 기준으로 서버의 상태를 모니터링하기 때문에, 서버의 API 호출 상태를 모니터링하기 어려운 기술적인 요소도 고려해야 한다.
비즈니스 객체를 리소스로 취급하기
두 번째 관점은 비즈니스 객체를 리소스로 취급하는 것이다. 이 관점에서는 비즈니스 객체의 상태를 HTTP 상태 코드로 반환한다. 흔히 알고 있는 REST 원칙을 따르는 설계에 해당한다. 예를 들어 GET /user/{id} 를 호출했을 때, id 에 해당하는 사용자가 존재한다면 200 OK, 존재하지 않는다면 404 Not Found 를 반환한다. 존재하지 않거나 삭제된 사용자를 조회하는 것이 예외 상황이 아니라고 판단한다면 상황에 따라 204 No Content 를 반환 할수도 있다.
REST 에 기반한 설계는 API 를 사용자가 이해하기 쉽게 계층화 할 수 있는 직관적인 설계 방법이지만 앞서 말한 상태 코드의 모호성은 여전히 해결할 수 없다. 따라서 그러한 모호함을 해결하기 위해 상태 코드와 별도로 예외 상황에서 응답 바디에 비즈니스 예외에 대한 상세한 정보를 제공하여 클라이언트가 명확한 정보를 얻을 수 있도록 하여야 한다.
결론

다소 허무하지만 결론은 ‘상황에 따라 다르다’ 이다. 이전 단락에서 언급한 두 가지 관점 말고도 프론트엔드에서 호출하는 API 냐, 서버에서 호출하는 API 냐에 따라 상태 코드를 다르게 정의할 수도 있다.
일례로, 프론트엔드 환경에서는 네트워크나 클라이언트 문제로 같은 요청이 여러 번 호출될 수 있으므로 결제 요청 등 멱등하게 처리되어야 하는 연산에 대해 상태 코드 또한 멱등하게 구현하는 것이 좋을 수 있다. 한편, 서버간 호출하는 API 라 해도 exactly-once 를 보장하지 않는 이벤트 기반의 분산 처리 시스템이라면 마찬가지로 멱등성을 상태 코드에도 확장해 200 OK 를 반환하는 것도 가능하다.
REST 도 결국 하나의 설계 원칙이지 정답은 아니다. Under-Fetching, Over-Fetching 등 REST 의 문제점을 보완할 수 있는 GraphQL, gRPC 와 같은 대체 기술도 엄연히 존재한다. 따라서 어떤 응답이 정답인지 집착하기 보다 API 가 사용되는 환경을 고려하고, 사용자 입장에서 이해하기 쉽고, 일관성을 느낄수 있는 정책과 구조로 API 를 설계하는 것이 더 중요하다고 생각한다.
참고자료
If a client calls the HTTP DELETE method twice on the same resource like DELETE /resource/{id}, what response code should the server return? Should it be 404 Not Found since it’s a deletion request for a ‘non-existent resource’? Or could it be 200 OK since it’s an idempotent operation of ‘deleting something already deleted’?
Is HTTP DELETE Idempotent?
In mathematics, idempotent refers to a function that satisfies f(f(x)) = f(x). In other words, applying the function multiple times doesn’t change the ‘result’. According to RFC7231, among HTTP methods, the idempotent methods include GET, PUT, and DELETE. GET is naturally idempotent since it’s a query operation. PUT creates or updates a resource, and calling it multiple times on the same resource results in the same resource state. Similarly, DELETE will leave the resource in a deleted state regardless of how many times it’s called.
On the other hand, non-idempotent methods include POST and PATCH. POST creates resources, and calling the same request multiple times creates multiple resources, making it non-idempotent. Meanwhile, PATCH partially updates resources. For example, if you send multiple requests via PATCH method to add products to a user’s shopping cart, the same product will be added multiple times, making it non-idempotent.
Properties of HTTP Methods
The meaning of HTTP idempotency can be examined in more detail in RFC7231 4.2.2, where the key point is that the ‘result’ of idempotency refers to the state of the resource (server). Therefore, idempotency is not guaranteed for response codes or response bodies - this is a matter of choice. In other words, while the DELETE method is idempotent, the response code and response body may not be idempotent.
The Ambiguity of HTTP Status Codes as API Specifications
Early HTTP was designed to handle requests for files or documents on servers. Therefore, response codes were fundamentally created to represent the state of files or documents on remote servers. For example, 404 Not Found literally indicates that the resource at the URI requested by the client doesn’t exist on the server, and 201 Created indicates that a resource has been created on the server.
In APIs designed based on REST principles, resources often represent business objects rather than files or documents. While most business object states can be mapped to response codes, sometimes non-business logic intervenes, making the meaning of status codes ambiguous. For example, when calling GET /resource/{id} and receiving 404 Not Found, you might intuitively think that the object corresponding to the id doesn’t exist, but it could actually be that the WAS returned 404 Not Found because there’s no code on the server to handle that request. In this case, the client might misunderstand that the resource doesn’t exist.
This problem fundamentally occurs because two layers - communication between client and WAS, and the results of internal application business logic - are handled with a single HTTP response. When developers implement functions like creation, deletion, and modification of resources in code, they define corresponding methods and responses for each function and implement exceptions supported by the language as needed. However, when exposing this via HTTP protocol, access to each method must be expressed as URIs, and method responses must be expressed as bodies and status codes, causing inconsistencies during the conversion process.
Various Perspectives on HTTP Status Code Selection for APIs
Considering the points mentioned earlier - ‘idempotency applies only to server state’ and ‘HTTP status codes cannot clearly correspond to all business states’ - there’s no definitive answer to how status codes should be defined when designing APIs exposed via HTTP. However, we can consider several perspectives based on the environment where the API is used and user convenience.
Treating the Server’s API Itself as a Resource
The first perspective is to treat only the API provided by the server as a resource. From this perspective, since the API itself is the resource, as long as the client successfully calls the API, it returns 200 OK as the status code. For other business exception situations, it maintains 200 OK while including information about the exception situation in the response body. 404 Not Found occurs when the client actually calls an API that doesn’t exist on the server.
In this approach, clients always receive 200 OK when calling APIs, which resolves ambiguity about status codes. However, clients must parse the response body to handle exception situations, increasing the client’s burden. Additionally, since most server monitoring tools monitor server status based only on status codes, technical factors that make it difficult to monitor API call status should be considered.
Treating Business Objects as Resources
The second perspective is to treat business objects as resources. From this perspective, the state of business objects is returned as HTTP status codes. This corresponds to commonly known REST-principled design. For example, when calling GET /user/{id}, if a user corresponding to the id exists, it returns 200 OK; if not, it returns 404 Not Found. If querying non-existent or deleted users isn’t considered an exception situation, it might return 204 No Content depending on circumstances.
REST-based design is an intuitive design method that allows APIs to be layered in an easily understandable way for users, but it still can’t resolve the status code ambiguity mentioned earlier. Therefore, to resolve such ambiguity, detailed information about business exceptions should be provided in the response body during exception situations, separate from status codes, so clients can obtain clear information.
Conclusion
Though somewhat anticlimactic, the conclusion is ‘it depends on the situation’. Beyond the two perspectives mentioned in the previous section, status codes could be defined differently depending on whether it’s an API called from the frontend or from servers.
For instance, in frontend environments, the same request might be called multiple times due to network or client issues, so for operations that must be handled idempotently like payment requests, it might be good to implement status codes idempotently as well. Meanwhile, even for APIs called between servers, if it’s an event-based distributed processing system that doesn’t guarantee exactly-once delivery, it’s possible to extend idempotency to status codes and return 200 OK.
REST is ultimately just one design principle, not the absolute answer. Alternative technologies like GraphQL and gRPC that can complement REST’s problems such as Under-Fetching and Over-Fetching certainly exist. Therefore, rather than obsessing over which response is correct, I think it’s more important to design APIs with policies and structures that consider the environment where the API is used, are easy to understand from the user’s perspective, and provide a sense of consistency.